COVID-19 感染者数プロファイルの概形
[東京都: 7月18日]
Modeled Profiles for COVID-19 affected numbers [Tokyo: July 17, 2020]
ロジスティック(logistlic)関数を,報告された東京都の累計の感染者数に最適化しました。第2波の最適化により得られたロジスティック関数モデルのパラメーターから,SIRD compartment モデルのパラメーターを得て,両者を比較しました。
報告値は,東京都が7月19日に発表した感染者数のうち,17日までは確定日別のデータを,18日は発表ベースの値をもとに,日別の累計感染者数としました。最適化の結果とその見方は,前日のブログをご覧ください。
SIRD モデルでは,ある感染者の集団について,
感受性者 Susceptible βSI →
感染者 Infectious γI → 元感染者 Recovered ; μI →死亡者 Death
のように4つの群に分けます。それぞれの群の人数を群のイニシャルで表します。各群の人数の合計 P が集団の大きさを決める人数です。また,感受性者から感染者への移行の速さに β,感染者から元感染者への移行の速さ(感染惹起日数の逆数)に γ,感染者から死者への移行の速さに μ を用います。
ロジスティック関数の内的自然増加率 r,および感染惹起日数 τ の値7から,SIRD モデルの β と γ を求めました。致死率が4%に近くなるように μ を決めました(若い年代で感染者が増えているので致死率はこれよりは低くなるでしょう)。集団のサイズ P は,I+R+D がロジスティック関数の(累計)感染者数 N と環境サイズ K に等しくなるよう決めました。
図から,感染者数のプロファイルから,時間の経過に伴う感染者数などの推移を概観できます。現段階では, 内的自然増加率 r はかなり精度よく求まってきましたので,プロファイルの概形は決まってきました。しかし,環境サイズ K と感染のピーク(変曲点)の日付の精度はまだ不十分です。
なお,このブログで記述する内容は,非専門家の私が個人的に構成したもので,正確さには努めてはおりますが,綿密に検証されたものではありません。また,将来の予測となるものでもありません。
図から,感染者数のプロファイルから,時間の経過に伴う感染者数などの推移を概観できます。現段階では, 内的自然増加率 r はかなり精度よく求まってきましたので,プロファイルの概形は決まってきました。しかし,環境サイズ K と感染のピーク(変曲点)の日付の精度はまだ不十分です。
なお,このブログで記述する内容は,非専門家の私が個人的に構成したもので,正確さには努めてはおりますが,綿密に検証されたものではありません。また,将来の予測となるものでもありません。
図1は,こうして求めたパラメーターによるSIRDモデルの計算結果(連立微分方程式の解法はRK4数値計算)です。-dS/dt が日別の感染者数(S の減少分,すなわちの I+R+D 増加分)です。
 |
| Fig. 1. SIR model for Tokyo COVID-19 affected numbers as of July 18, 2020[クリックで拡大] |
図2は,最適化した累計感染者数 N と日別の感染者数 dN/dt ,対応するSIRDモデルの累計感染者数 I+R+D と日別の感染者数-dS/dt です。
 |
| Fig. 2. SIR-modeled affected numbers from the optimized logistic-function model [クリックで拡大] |
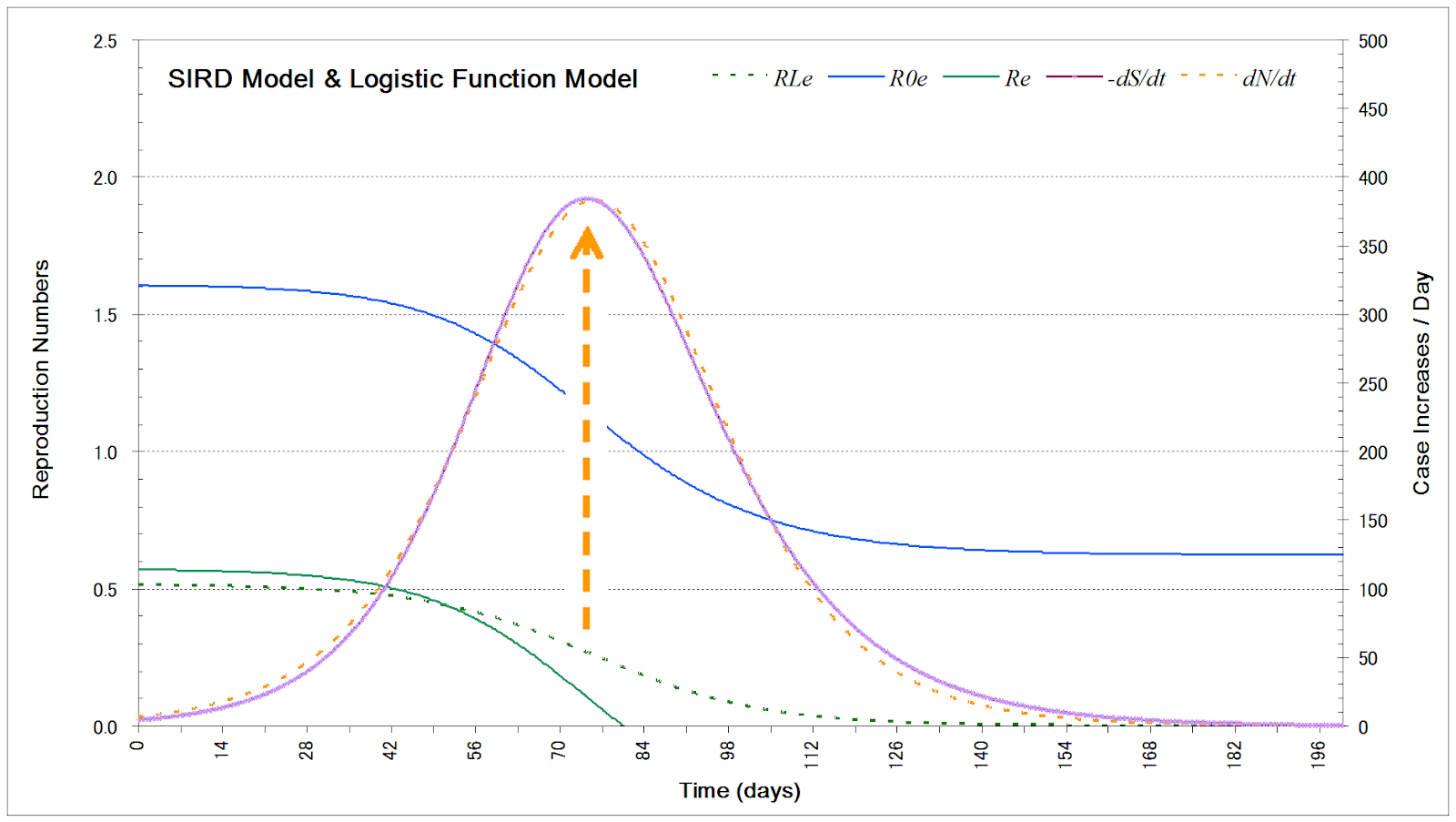
図3は,ロジステック関数からの日別感染者数と実効再生産数 RLe,SIRモデルでの日別感染者数と実効再生産数 R0e と Re です。実効再生産数 RLe がこのブログで定義して用いているもので,dN/dt = (1/τ) RLe I の式の累計感染者数 N の増減を示す項です。
実効再生産数 R0e は R0(S/P) で,基本再生産数 R0 から時間経過(感受性者数 S の減少)に伴って算出されるものです。よく使用される実効再生産数R0eとここでのRLeの関係は R0e ≈ 2RLe-τr+1 です。Re は R0e-1 で,dI/dt = γ Re I の式の感染者数 I の増減を示す項です。
 |
| Fig. 3. Daily cases of affected numbers and reproduction numbers [クリックで拡大] |
最適化した関数から計算される内的自然増加率 r から計算される"τ×増加率"がこのブログでの実効再生産数です。初期の頃の"τ×増加率"に1を加えた数が基本再生産数R0 に対応すると考えられ,R0 ≈ τr+1 です。東京都の第1波では2,第2波では1.55程度です。
日別感染者数がピークに達するとき,累計感染者数と"τ×増加率"は変曲点に来ます(矢印)。時間が経過すると0に収束します。変曲点に来ると,実効再生産数の"τ×増加率"が初めの頃の値の1/2となります。
SIRD モデルの基本再生産数と実効再生産数は感染者数 I に関するもので, R0e と Re は感染者数のピークの日付に前者は1,後者は0となります。しかし,日別の感染者数のピークとは合致せず,遅れがあります(図1および図3)。 感染者の数のピークは,感染者数の変化量のピーク(変曲点)から,東京都の場合は7日ほど,遅れて到来します。変曲点から2週間程度は感染力を持つ感染者の数 I は最も多い状態にあります。この期間にことさら注意すべきで,感染者数(I+R+D)のピークを過ぎてからクラスターがなぜ発生し易いかも理解できると思います。
図3をよく見ると,28日あたりでロジスティック関数値が少し大きめ,126日当たりで少し小さめです。この様子が解析にも表れているように見受けられます。Gompertz 関数ならば,SIRD モデルの日別の感染者数への合致が改善されるかもしれません。ただ,実際のデータのばらつきと確度,最適化の簡便さ,SIRD モデルへの適用性から,ロジスティック関数が適していると考えています。
SIRD モデルも含めたcompartmentモデルの問題点は,計算にあたって,集団の大きさを決める人数 P の値が必要なことです。この値を東京都の人口などと仮定すると,数百万,数十万の感染者数の値(数万人の死者などの値)が出てきてしまいます。
私のロジスティック関数の最適化では, 環境サイズ K を仮定しないで,最適化から求めています。また,増幅率と実効再生産数も環境サイズに依存しないため,compartmentモデルのような問題点はありません。たとえば,日本全体の実効再生産数は東京都の値とほぼ等しいので,両者の感染プロファイルは互いに近いものとなります。変曲点と環境サイズはそれぞれの最適化から算出されます。







